边缘计算中的机器学习:基于 Linux 系统的实时推理模型部署与工业集成!

你好,旅行者!欢迎来到 Medium 的这一角落。在本文中,我们将把一个机器学习模型(神经网络)部署到边缘设备上,利用从 Modbus TCP 寄存器获取的实时数据来预测一台复古音频放大器的当前健康状况。你将学习如何训练模型、导出模型,并在基于 Linux 的系统上运行实时推理,并通过MQTT 发布结果。这是一个简单但完整的流程——从工作站上的建模到在边缘设备上运行工业风格的推理。
虽然需要了解 Linux、基础网络、Python 和机器学习包的使用,但本文提供了示例代码,你可以按自己的节奏逐行学习。
架构
首先,在开始之前我们需要将想法具体化。经过了一次长达 5 分钟、令人筋疲力尽的头脑风暴后,我们可能已经有了一个大致的方向。然而,在推进之前,建议先为我们的项目定义一个架构。
无论是出于个人目标、学术实践还是实际商业案例项目,拥有一个路线图,明确我们要去哪里、为什么去以及如何去,都是非常有帮助的。
硬件堆栈
有哪些硬件可用?软件提供了更多的灵活性,通常有不同的选项来做同样的事情,但是这种额外的好处大部分时间取决于我们的项目可以使用什么样的硬件。也许我们在家里没有太多的选择,只有一些主板,或者在专业环境中,客户的项目预算可能会定义为确定的解决方案可以购买哪种设备。
我们所需的硬件包括:
笔记本电脑/工作站(这些测试使用 Windows 操作系统,但如果你愿意并知道如何操作,可以在任何 Linux 发行版上使用等效软件)
树莓派3,甚至可能是 2
以太网电缆
软件堆栈
好的,在定义了一个友好且易于访问的硬件设置后,让我们来谈谈软件。
树莓派模块使用 Raspbian 作为其操作系统,实际上它只是 Debian 的一种变体,而 Debian 是一种 Linux 发行版(意味着它使用 Linux 内核)。

有些 Linux 发行版确实非常专注于特定领域的适配,但幸运的是,Debian 和 Raspbian 是最流行且易于访问的发行版之一。它们之间有很多不同,但要知道著名的 Ubuntu 操作系统也是基于 Debian 的。
这意味着我们可以轻松地从全球社区中找到大量软件来实现我们的目标(或将其作为构建的工具或自己的工具)。
在本例中,我们将使用:
- Python 3.9+,作为编程语言
- pyModbusTCP,用于通过 ModbusTCP 工业协议进行通信
- paho-mqtt,用于通过 MQTT 发布/订阅协议进行通信(在物联网应用中非常流行)
- tensorflow & scikit-learn,用于开发、训练和导出/导入/使用推理模型
- joblib,帮助我们导入导出的模型
- numpy,帮助我们管理模型中的数值数据结构,是机器学习中非常强大且必不可少的库
- pandas,用于数据管理和处理,对数据科学和机器学习也非常有用
- matplotlib,用于可视化:生成图表和绘图
- Mosquitto Broker,一个可靠的 MQTT 代理,用于发布我们的模型结果
- QModMaster,一个 ModbusTCP 主站模拟器,用于测试我们的主/从通信
先决条件配置和安装
在继续之前,最好先准备好一切。你也可以稍后再回顾这一部分,但提前做好准备将有助于你顺利地跟随本文的进度。携手共进吧。
在笔记本电脑/工作站上:
1.确保系统上已安装 Python,如果没有,请从 此处 下载并按照推荐的官方安装说明进行安装。
https://www.python.org/downloads/release/python-3100/
2.在 Documents 目录下启动一个 shell 或导航到该目录
cdDocuments
为本项目创建一个目录并导航到该目录:
mkdirml_edge_projectcdml_edge_project
创建一个 Python 虚拟环境:
python-m venv .venv
激活虚拟环境:
sourceactivate venv
下载并安装所需的 Python 库/包:
pipinstall paho-mqtt pandas numpy scikit-learn tensorflow matplotlib
下载并解压 QModMaster 桌面应
https://sourceforge.net/projects/qmodmaster/
使用静态 IPv4 地址配置机器的以太网端口。本例中使用 192.168.1.200。
在树莓派上:
1.确保系统上已安装 Python,如果没有,请从 此处 下载并按照推荐的官方安装说明进行安装。
https://www.python.org/downloads/release/python-3100/
2.在 Documents 目录下启动一个 shell :
cdDocuments
为本项目创建一个目录并导航到该目录:
mkdirml_edge_projectcdml_edge_project
创建一个 Python 虚拟环境:
python-m venv .venv
激活虚拟环境:
sourceactivate venv
下载并安装所需的 Python 库/包:
pipinstall pyModbusTCP paho-mqtt tensorflow joblib numpy
下载、安装并启用 Mosquitto MQTT Broker:
sudo apt update && sudo apt upgradesudo apt install -y mosquitto mosquitto-clientssudo systemctlenablemosquitto.service
验证 Mosquitto 安装(打印版本):
mosquitto-v
配置访问(基本上允许所有访问,仅用于测试):
sudo nano /etc/mosquitto/mosquitto.conf
在文件末尾插入以下行:
listener1883allow_anonymoustrue
保存并退出。
1.使用静态 IPv4 地址配置边缘设备的以太网端口。本例中使用 192.168.1.75。

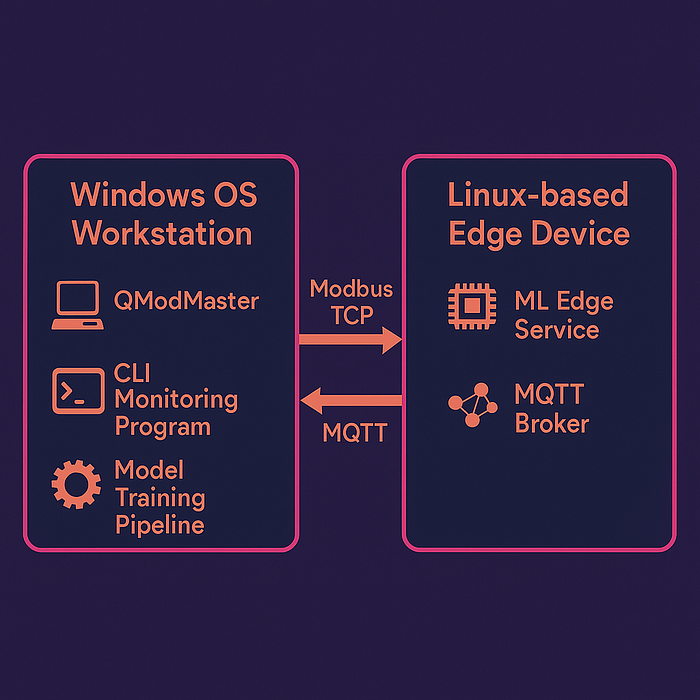
图表
我们已经有了硬件和软件列表,现在让我们以视觉化的方式呈现,以便于后续跟进。
此图表以更有趣、清晰和高效的方式包含了我们刚才指定的所有内容。
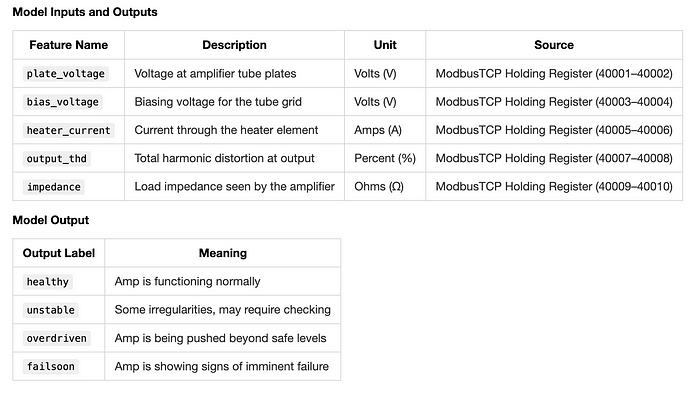
数据映射
任何项目都需要一个数据映射。它可以简单到一张标注了“输入和输出”的餐巾纸,也可以是一张更专业、更美观的表格/文档,包含各种列,如名称、标签、数据类型、协议、寄存器、源、目标、描述等。
让我们使用这个用于我们的实践:
Modbus TCP
我们知道推理服务的输入数据将来自一个 ModbusTCP 主站(由 QModMaster 模拟),该主站将写入我们虚拟 ModbusTCP 从站设备的寄存器。然后,我们将循环读取这些寄存器中的数据,将其从两个独立的 16 位寄存器转换为一个单一的 32 位浮点值,以便我们的模型更容易处理。
在先决条件步骤中,我们已经准备好了环境,现在开始工作。
在工作目录中,创建一个名为 ml_edge_service.py 的文件,并使用你喜欢的编码 IDE 或文本编辑器插入以下代码:
frompyModbusTCP.clientimportModbusClientimportstructimporttime
# Modbus Clientmodbus_client = ModbusClient(host="192.168.1.75", port=502, auto_open=True)# Function to read 32-bit float from 2 Modbus registersdefread_float(start_address): regs = modbus_client.read_holding_registers(start_address,2) ifregs: returnstruct.unpack('>f', struct.pack('>HH', regs[0], regs[1]))[0] returnNone
MQTT
为了使我们的模型推理结果可用,我们可以将它们发布到我们想要的任何 MQTT 主题(只要遵循主题命名和语法规则),但首先我们需要让 Mosquitto MQTT 代理运行起来。
为此,我们现在修改 ml_edge_service.py,添加 MQTT 发布函数,使其看起来像这样:
importpaho.mqtt.clientasmqtt
# MQTT Clientmqtt_client= mqtt.Client()mqtt_client.connect("localhost",1883,60)
我们的 ml_edge_service.py 文件已经部分准备好了,它还需要核心部分,即推理模型。我们先保存脚本,然后继续处理它。
数据
首先,我们获取实践项目的数据 data.csv,并将其放在与 ml_edge_service.py 脚本相同的目录中。此数据已经过清理,但要知道在实际问题中,数据工程过程确实是问题的一部分。数据几乎从来不会从源头直接变得干净。
下载复古放大器健康数据集 >>> [此处]
https://drive.google.com/drive/folders/1wO_uaqUrUKWfm77W35Jeu5Qe64ujZRlE?usp=sharing
对于建模阶段,我们将使用 data.csv 文件。
让我们在工作目录中创建一个名为 model.py 的新脚本,并开始编写第一行代码。添加以下内容:
importpandasaspdimportnumpyasnpfromsklearn.model_selectionimporttrain_test_splitfromsklearn.preprocessingimportLabelEncoder,StandardScalerimportjoblib
# Load and encode datasetdf= pd.read_csv("data.csv")le = LabelEncoder()df['status_encoded'] = le.fit_transform(df['status'])# Features and labelsX = df.drop(['status','status_encoded'], axis=1).valuesy =df['status_encoded'].values# Normalizescaler = StandardScaler()X_scaled = scaler.fit_transform(X)joblib.dump(scaler,"scaler.save")# SplitX_train, X_temp, y_train, y_temp = train_test_split(X_scaled, y, test_size=0.3, random_state=42)X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)
构建
现在,是时候定义我们模型的结构了。由于在这个实践项目中我们处理的是非线性关系和数值输入,我们将使用一个简单的神经网络(顺序密集层)。这些网络通常足以接收连续的传感器输入并输出离散状态,同时保持复杂性较低。
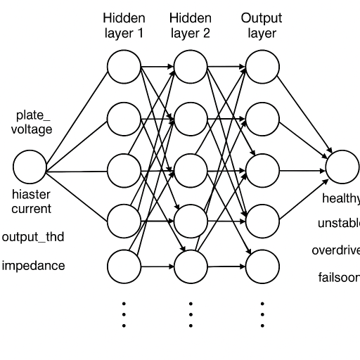
将以下代码块插入到 model.py 脚本中:
# MODEL BUILDING STAGE# ---------------------importtensorflowastf
model= tf.keras.Sequential([ tf.keras.layers.Dense(64, activation='relu', input_shape=(5,)), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(16, activation='relu'), tf.keras.layers.Dense(4, activation='softmax')])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
这个模型架构对于测试目的来说应该足够了。让我们继续添加训练逻辑。
训练
为了训练我们的模型,让我们添加以下代码块:
# TRAINING STAGE# --------------history= model.fit(X_train, y_train, epochs=50, validation_data=(X_val, y_val))
在这里,我们将训练模型 50 个 epoch(数据是合成的且规模较小,因此学习速度会很快),并存储指标历史记录,然后绘制/分析它们并评估模型的训练/验证性能。
测试
训练后,我们想在未见过的数据(除了验证数据之外)上测试我们的模型,因此让我们添加一些代码:
# TESTING STAGE# -------------
importmatplotlib.pyplotasplt# Evaluate the model on test dataloss, acc = model.evaluate(X_test, y_test)print(f"Test Accuracy:{acc:.2f}")# Plot training historyplt.figure(figsize=(12,5))# Accuracy plotplt.subplot(1,2,1)plt.plot(history.history['accuracy'], label='Train Acc')plt.plot(history.history['val_accuracy'], label='Val Acc')plt.title('Model Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.grid(True)# Loss plotplt.subplot(1,2,2)plt.plot(history.history['loss'], label='Train Loss')plt.plot(history.history['val_loss'], label='Val Loss')plt.title('Model Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)# Save and show the plotplt.tight_layout()plt.savefig("training_history.png")plt.show()
导出
现在,让我们在测试完成后添加几行代码来导出我们的模型,以便我们可以在目标设备(ED-IPC/RasPi)上使用它。
# EXPORTATION STAGE# ------------------model.save("amp_model.h5")
完成的 model.py 脚本
importpandasaspdimportnumpyasnpfromsklearn.model_selectionimporttrain_test_splitfromsklearn.preprocessingimportLabelEncoder,StandardScalerimporttensorflowastfimportjoblibimportmatplotlib.pyplotasplt
# Load datadf= pd.read_csv("data.csv")# Encode targetle = LabelEncoder()df['status_encoded'] = le.fit_transform(df['status'])# Features and labelsX = df.drop(['status','status_encoded'], axis=1).valuesy =df['status_encoded'].values# Normalize featuresscaler = StandardScaler()X_scaled = scaler.fit_transform(X)joblib.dump(scaler,"scaler.save")# Split datasetX_train, X_temp, y_train, y_temp = train_test_split(X_scaled, y, test_size=0.3, random_state=42)X_val, X_test, y_val, y_test = train_test_split(X_temp, y_temp, test_size=0.5, random_state=42)# Build modelmodel = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation='relu', input_shape=(5,)), tf.keras.layers.Dense(32, activation='relu'), tf.keras.layers.Dense(16, activation='relu'), tf.keras.layers.Dense(4, activation='softmax')])model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])# Train modelhistory= model.fit(X_train, y_train, epochs=50, validation_data=(X_val, y_val))# Evaluate modelloss, acc = model.evaluate(X_test, y_test)print(f"Test Accuracy: {acc:.2f}")# Plot training historyplt.figure(figsize=(12, 5))# Accuracy plotplt.subplot(1, 2, 1)plt.plot(history.history['accuracy'], label='Train Acc')plt.plot(history.history['val_accuracy'], label='Val Acc')plt.title('Model Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy')plt.legend()plt.grid(True)# Loss plotplt.subplot(1, 2, 2)plt.plot(history.history['loss'], label='Train Loss')plt.plot(history.history['val_loss'], label='Val Loss')plt.title('Model Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.grid(True)# Save and show the plotplt.tight_layout()plt.savefig("training_history.png")plt.show()# Export modelmodel.save("amp_model.h5")
太好了。我们的代码已经准备好运行了!完整的流程应该导入并准备我们的数据集,构建模型,训练它(同时运行验证),测试它,给我们一些指标,并将模型保存为文件。
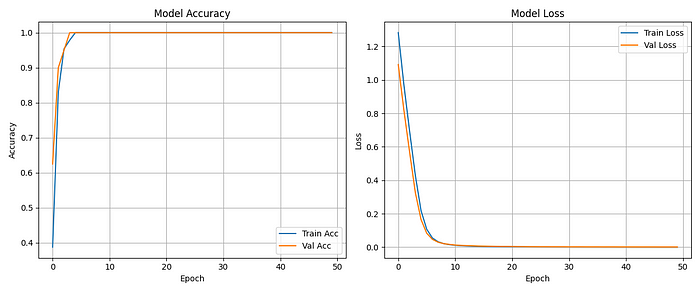
在上面,你可以看到我从这个流程中得到的结果,它足够好,可以在线测试(将其部署为服务运行),这显然是因为我们的数据集是合成的。
部署
从 Python 脚本调用导出的模型
好的,让我们回到 ml_edge_service.py 脚本,并添加几行缺失的代码。
这些行将负责加载我们之前导出的模型,并使其随时可以接收数据并输出一些推理结果,当然,是作为服务持续运行的。
添加以下内容:
importtensorflowastfimportnumpyasnpimportjoblib
# Load model and scalermodel = tf.keras.models.load_model("amp_model.h5")scaler = joblib.load("scaler.save")labels = ["healthy","unstable","overdriven","failsoon"]while True: plate_voltage = read_float(0) bias_voltage = read_float(2) heater_current = read_float(4) output_thd = read_float(6) impedance = read_float(8) if None not in (plate_voltage, bias_voltage, heater_current, output_thd, impedance): X = np.array([[plate_voltage, bias_voltage, heater_current, output_thd, impedance]]) X_scaled = scaler.transform(X) prediction = model.predict(X_scaled) label = labels[np.argmax(prediction)] mqtt_client.publish("amp/inference", label) time.sleep(1)
完成的 ml_edge_service.py 脚本
这是最终的 ml_edge_service.py 脚本的样子:
frompyModbusTCP.clientimportModbusClientimporttimeimportstructimporttensorflowastfimportnumpyasnpimportjoblibimportpaho.mqtt.clientasmqtt
# Modbus Clientmodbus_client = ModbusClient(host="192.168.1.75", port=502, auto_open=True)# MQTT Clientmqtt_client = mqtt.Client()mqtt_client.connect("localhost",1883,60)# Load model and scalermodel = tf.keras.models.load_model("amp_model.h5")scaler = joblib.load("scaler.save")# Function to read 32-bit float from 2 Modbus registersdefread_float(start_address): regs = modbus_client.read_holding_registers(start_address,2) ifregs: returnstruct.unpack('>f', struct.pack('>HH', regs[0], regs[1]))[0] returnNonelabels = ["healthy","unstable","overdriven","failsoon"]whileTrue: plate_voltage = read_float(0) bias_voltage = read_float(2) heater_current = read_float(4) output_thd = read_float(6) impedance = read_float(8) ifNonenotin(plate_voltage, bias_voltage, heater_current, output_thd, impedance): X = np.array([[plate_voltage, bias_voltage, heater_current, output_thd, impedance]]) X_scaled = scaler.transform(X) prediction = model.predict(X_scaled) label = labels[np.argmax(prediction)] mqtt_client.publish("amp/inference", label) time.sleep(1)
将 Python 脚本执行设置为系统服务
我们的 ml_edge_service.py 脚本现在已经完成了,不可避免地,现在让我们将其配置为作为系统服务运行。
为了实现这一点,让我们在 systemd 目录中直接创建一个名为 ml_edge_service.service 的服务文件(你可能需要 sudo 权限来执行此操作):
sudo nano/etc/systemd/system/ml_edge_service.service
将以下代码粘贴到其中:
[Unit]Description= ML Amplifier Health Inference Model ServiceAfter=network.target
[Service]ExecStart=/usr/bin/python3 /home/pi/Documents/ml_edge_project/ml_edge_service.pyWorkingDirectory=/home/pi/Documents/ml_edge_project/Restart=alwaysUser=pi[Install]WantedBy=multi-user.target
保存并退出,现在它位于其他服务所在的位置。你现在可以在打开的系统 shell 中使用以下命令来启动它:
sudo systemctl daemon-reexecsudo systemctl daemon-reloadsudo systemctlenableml_edge_servicesudo systemctl start ml_edge_service
你可以使用以下命令来监控服务:
sudosystemctl status ml_edge_service
还可以使用以下命令来停止和重启服务:
sudosystemctl stop ml_edge_servicesudo systemctl restart ml_edge_service
使用 QModMaster 喂养和测试推理模型服务
现在,我们已经在边缘设备(ED-IPC/RasPi)上启动并运行了服务,等待一些数据来输入,让我们启动一个 QModMaster 实例,并将其设置为向我们的 ModbusTCP 从站(在边缘设备上)写入值。
首先,配置目标从站 IP,并确保设置正确,如下所示。
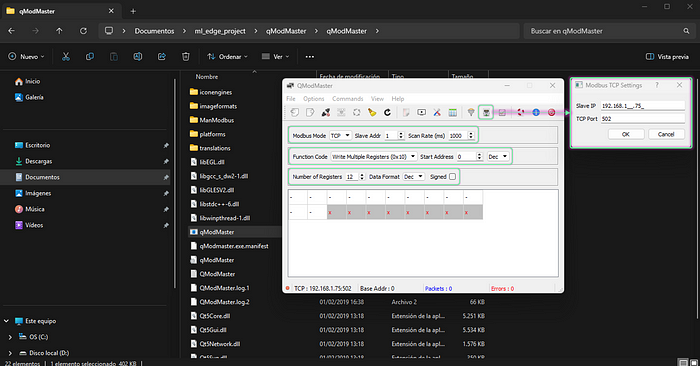
然后继续连接,并启用循环更新。之后开始写入值,使用图像中的示例作为第一个示例,或使用之前与 data.csv 文件一起提供的 test_samples.csv 文件中的任何示例。
我正在使用下面显示的示例行。我们预计会收到模型对该输入数据的推理结果为“healthy”。

服务应该自动读取并处理 ModbusTCP 从站寄存器中的数据,将其输入到模型中,并输出一些结果供我们查看。让我们找出如何查看它们。
监控
CLI 应用读取并打印结果
我们知道,现在我们的模型结果正在发布到 amp/inference 主题,并且可以在运行在边缘设备(ED-IPC/RasPi)上的 Mosquitto MQTT 代理的地址上获取。因此,让我们从笔记本电脑/工作站上读取它们,就像我们是一个试图获取并利用这些结果的客户端一样。
在你的笔记本电脑/工作站工作目录中创建一个名为 ml_edge_monitoring.py 的脚本,并插入以下代码:
importpaho.mqtt.clientasmqtt
def on_message(client, userdata, msg): print(f"[INFERENCE] {msg.payload.decode()}")mqtt_client = mqtt.Client()mqtt_client.connect("192.168.1.75",1883,60)mqtt_client.subscribe("amp/inference")mqtt_client.on_message = on_messagemqtt_client.loop_forever()
现在运行脚本,你应该会看到模型结果定期输出,实际上几乎是实时的(不要太认真对待实时部分)。
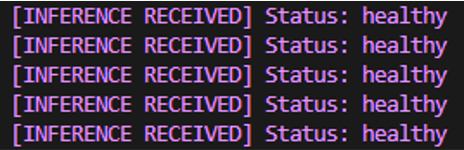
……就这样,一个完全功能的机器学习推理模型作为服务运行在基于 Linux 的边缘设备上,供你使用!不过,先别急着卖掉它。还有很多事情要做……
不管如何,恭喜你!我为你达到这一点感到骄傲,冠军。
机会领域
还有许多其他事情我希望我能在本文中包含。这些可能是未来的主题,但这里有一些,你可以自己探索并打造一个杀手级的机器学习边缘服务。
OPC UA
集成 OPC UA 客户端功能,以实现更多工业通信协议兼容性。这是一个非常流行且广泛用于全球大型企业 OT 网络的行业标准协议。
使用 Python 的 opcua 库来利用这一点。
Docker

在不同设备或系统上运行遇到困难?不用担心,Docker 容器可以帮助你!
它们还可以为更高效的 CI/CD 管道提供方法,这将有利于你的模型部署。
甚至可以使用 Kubernetes 来编排这些容器,使一切稳定且可扩展。
FastAPI

一个聪明的方法是将数据提供给许多不同的应用程序,那就是提供一个 HTTP 服务器,该服务器响应你模型结果或指标的请求。非常适合监控和结果可视化(仪表板?)。
Dashboard

使用 Plotly 或 Grafana 等工具制作一些仪表板,有很多工具可供选择。每个人都喜欢一个外观美观、信息量和细节恰到好处的 UI。
Database

也许可以添加一个地方来存储你的模型结果和性能指标?数据库将是一个理想的选择!
SQLite 适合小型部署,或者你可以使用 PostgreSQL 来构建一个更大、更健壮的平台。
日志记录
厌倦了需要关注 CLI 结果和指标流,那就记录它们,以后再查看!或者甚至捕获运行时错误以供未来调试。
基本的日志文件变得太大,或饱和得太快?使用旋转日志文件!这些日志文件允许你拥有可覆盖的日志文件(甚至在达到大小限制时生成自定义数量的备份),它们会自我循环,不会随着时间的推移占用更多空间,而且永远不会停止。
在某些情况下,非常适合设置后忘记。
推荐
从一开始就了解你的数据的性质、属性和质量
本项目只是一个快速而有趣的提案,用于测试在工业环境中如果以适当和健壮的方式实现,可能会使用的各种技术。然而,要实现这种健壮性,最重要的步骤之一是确保你了解你的数据。花一些时间探索它,查看历史记录,了解其细微差别。
例如:
为什么我的数据中存在间隙?
为什么每隔一段时间就会出现如此怪异的峰值?
为什么在应该是数值输入的地方收到了字符串?
还有很多类似(或更糟(或更有趣))的例子
听起来很可笑,但这种情况比你想象的更常见。即使在专业环境中也是如此。
进行测试并构建健壮的管道(在数据到达你的模型之前)
考虑到最后一个建议,将帮助你意识到项目特定的问题,并因此促使你尝试(并成功,耶!)从一开始就开发出防错的管道,因为记住,即使模型正在运行并输出一些东西,也不意味着它是正确的。
原文地址:
https://medium.com/mcd-unison/machine-learning-on-the-edge-real-time-inference-model-deployment-and-industrial-integration-with-af7f2e5244dehttps://www.makeuseof.com/raspberry-pi-5-overclocking-guide/
相关文章
-
渔村跨江线路成功拆除 再现漓江山水画卷本色
-
不起眼的小伤口可能导致截肢!警惕这种喜欢寄生海洋生物的“隐藏杀手”→
-
总奖金达110万元!第三届漓江文学奖在桂林启动
-
知名女演员自曝:生完孩子长高2.5厘米,脚都大一码!专家:这几种情况还有机会
-
爆火刷屏!健美比赛混入175斤“小胖子”,圆滚滚的肚子引热议;本人回应:做健身行业9年,吃得多练得少心态好
-
桂林运动员在2025年全国青少年航空航天模型锦标赛中斩获佳绩
-
“哥哥再不发工资,我又要挨饿啦”
-
正在公示!广西拟表彰这50人
